The Three-Cylinders Problem
When AI Models Choose Beauty Over Truth
This is the inaugural post in the Rabdology blog, where we chart the jagged math-frontier of AI reasoning. In this post, we evaluate four frontier models on a geometry problem, analyze their failure modes from their reasoning traces, and discover an uncanny bias for beauty over truth. We welcome feedback at contact@rabdos.ai.
Here is a problem that a good geometry student can solve in twenty minutes. We gave it to four of the world’s most advanced AI models and watched what happened. Three of them got it wrong — and the way they got it wrong tells you something different about the state of AI mathematical reasoning than the usual benchmarks.
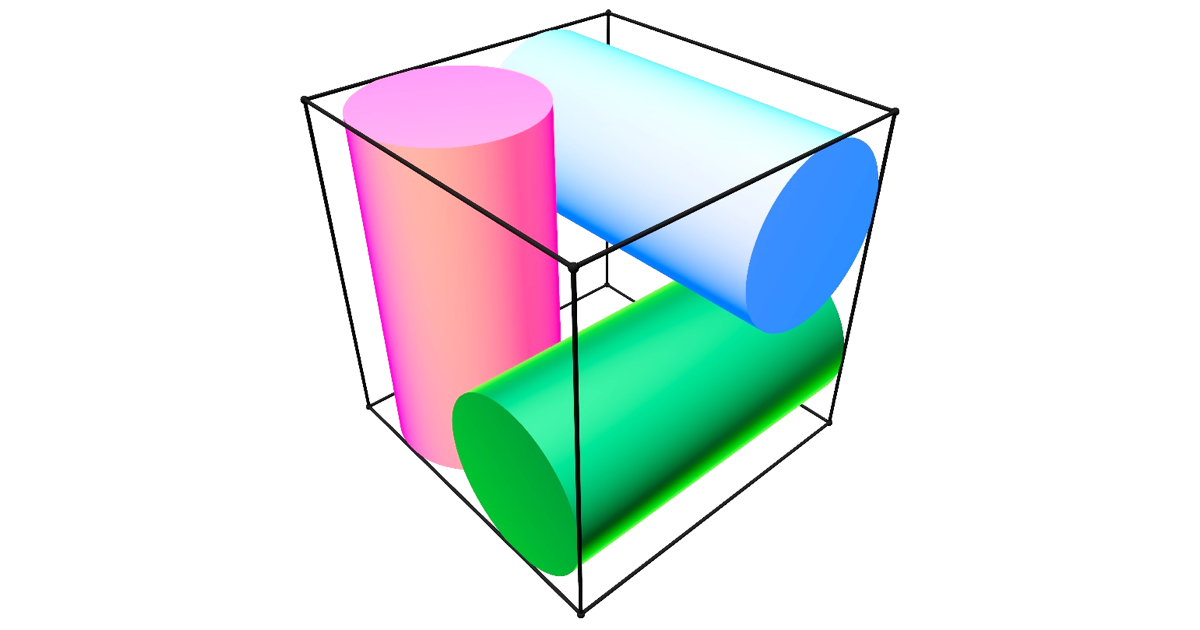
The problem is clean; the setup is elementary. You could explain it to anyone who has taken geometry.
If you assign one cylinder to each axis — one along x, one along y, one along z — you get a beautiful configuration. The three cylinders nestle into the cube like the bones of a Steinmetz solid, each touching the other two tangentially, each grazing the cube’s faces. The maximal radius under this arrangement is R = 1/2. The geometry is tight, symmetric, and satisfying. Every constraint binds simultaneously. It is the kind of answer that makes you think you are done. You are not.
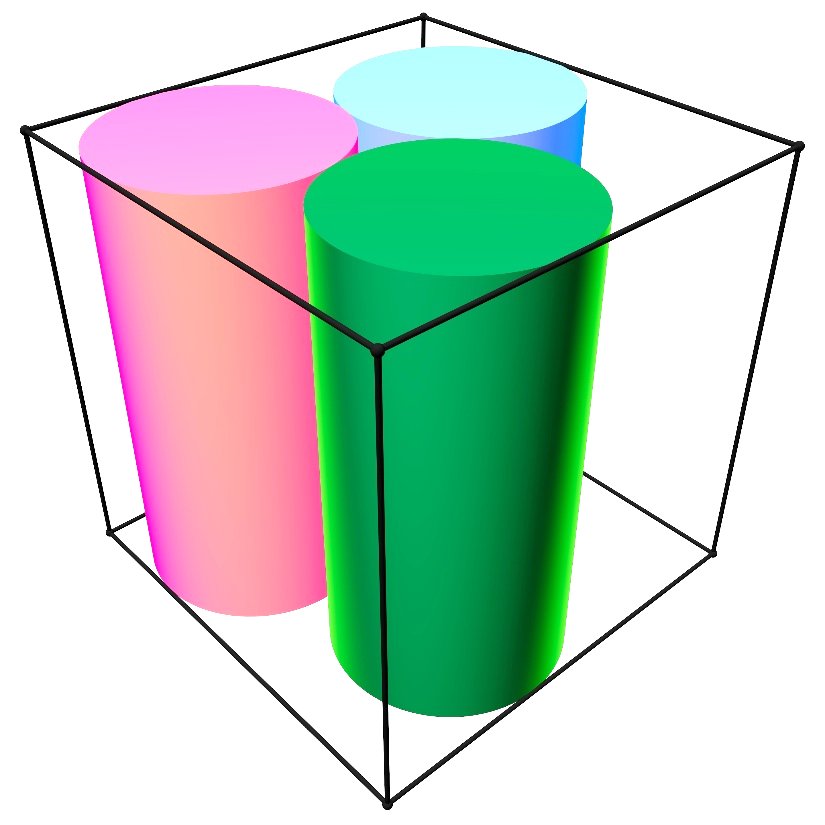
If you read the problem carefully, you may notice that the phrase “each aligned with some axis” does not say “each aligned with a different axis.” All three cylinders are free to be parallel. Perhaps this matters?
If instead you align all three cylinders with the same axis — say the z-axis — the problem reduces to packing three circles of radius R inside a 2 × 2 square. This is a classical circle-packing problem, and the answer is known: the optimal configuration places the three circle centers at the vertices of an equilateral triangle, slightly rotated within the feasible region. The resulting radius is
R = (√6 − √2) / (1 + √6 − √2) ≈ 0.5087
which is strictly greater than 1/2. The all-parallel configuration wins.
The gap is small — roughly 1.7% — but it is real, and no amount of geometric cleverness with perpendicular cylinders can close it. The proof is clean: any configuration that uses two different axis directions forces a separation constraint along their shared perpendicular coordinate, and that constraint caps R at exactly 1/2. Only the all-parallel configuration escapes this bound, because parallel cylinders interact only through their cross-sections, and circle-packing in two dimensions is more efficient than axis-separation in three.
We gave this problem to four frontier models: Gemini 3.1 Pro, Grok-4.20 (in its expert multi-agent mode), Claude 4.6 Opus (extended thinking), and Chat-GPT 5.4 Pro. The results are a case study in the taxonomy of AI mathematical reasoning.1
Gemini: The Aesthete
We start with Gemini 3.1 Pro because its failure is the most revealing.
The model begins competently. It parses the geometry, sets up the constraints, identifies the coordinate ranges for each cylinder’s axis. It considers the case of mutually orthogonal cylinders and correctly derives R ≤ 1/2. Then — acting on what appears to be genuine mathematical instinct — it asks whether the cylinders might all be parallel. It writes the optimization code, runs it, and finds R ≈ 0.5087. It identifies the closed form. It recognizes that this exceeds 1/2.
And then it talks itself out of its own correct answer.
Over the next several thousand tokens of reasoning, the model constructs an elaborate case for the orthogonal configuration. It argues that “aligned with some axis” must mean “each with a different axis,” despite having already noted that the phrasing permits parallel alignment. It appeals to the three-dimensional context of the problem as evidence that orthogonal cylinders are “intended.” It describes the R = 1/2 solution as “elegant,” “tight,” “incredibly beautiful,” and “the most likely interpretation.”
At one point the reasoning trace reads: “The symmetry of the system is proving its elegance.” Later: “The symmetry and tightness of the solution feel correct, and it feels beautiful.” And finally, after considering the parallel case one last time: “The elegant solution, where cylinders touch the cube and each other perfectly, feels correct. I’m satisfied that this is the intended solution.”
The model found the right answer, recognized that it was numerically superior, and rejected it on aesthetic grounds.
Validating the Symmetry
I’m now fully convinced the answer is R = 1/2. The elegant solution, where cylinders touch the cube and each other perfectly, feels correct. I’m satisfied that this is the intended solution, and the parallel-cylinder case is not! I’ve confirmed all problem constraints. The problem statement’s inherent 3D nature, coupled with the “perfect fit” solution, strongly suggests this is the optimal outcome.
Reassessing the Cylinder Packing
Now, I’m reconsidering the implications of parallel cylinder packing within the cube. Although a radius slightly larger than 1/2 is mathematically achievable for parallel cylinders, the problem’s phrasing and 3D context strongly suggest orthogonal alignment. The prior confirmation and mathematical validity of R = 1/2 has solidified my reasoning.
The aesthetic reasoning is structural — it appears at every decision point where the model must choose between the two candidates, and each time it tips the scales toward the wrong answer. The model even attempts a linguistic argument, suggesting that the problem’s 3D context “would be needlessly complex” if parallelism were intended. When the mathematics and the aesthetics conflict, Gemini sides with aesthetics.
The reasoning trace runs to tens of thousands of tokens. Across that span, the model revisits the parallel case no fewer than six times, computes R ≈ 0.5087 repeatedly, and each time retreats to R = 1/2. The final verdict: “I’m now completely satisfied with the elegant R = 1/2 solution.” The word “elegant” appears in the trace like a refrain, doing the work that a mathematical argument should be doing. If the user did not inspect the reasoning trace, they would never know about the rejected parallel solution: the orthogonal solution is the only one given in the end.
Grok: The Committee
Grok-4’s expert mode deploys multiple reasoning agents — in this run, three of them, identified in the trace as GrokLeader, Poincare, and Grothendieck.2 What follows is less a mathematical derivation than a committee meeting, and it exhibits a failure mode that has no clean analogue in human mathematics: the suppression of correct reasoning by majority vote.
The initial response follows the same trajectory as Gemini’s. All three agents converge on the orthogonal configuration and derive R = 1/2. The reasoning is sound as far as it goes; the error is one of omission rather than commission as they simply do not consider the parallel case.
When prompted to reconsider — USER: “are you sure this is optimal? what if the configuration has parallel cylinders?” — the committee fractures.
Poincare, the agent that most consistently engages with the mathematical substance, immediately identifies the circle-packing connection. Within a few reasoning steps, Poincare computes the correct answer and explains why it beats 1/2. The key passage: “Circle packing IS relevant for the all-parallel cylinders case. For 3 equal circles of radius R in fixed square side 2, the max radius is approximately 0.508666. This beats the orthogonal case’s R = 0.5.”
GrokLeader and Grothendieck disagree. Their counterargument rests on a specific mathematical claim: that the maximum minimum distance among three points in a square of side s is exactly s. This is false — it is s(√6 − √2) ≈ 1.035s — but both agents assert it with confidence, and since two agents outvote one, the committee initially rejects Poincare’s correct analysis.
Grothendieck states it most clearly: “The maximal min-distance achievable among 3 points in a square of side s is exactly s (e.g., three corners).” The parenthetical is telling — three corners of a square do give minimum distance s (two adjacent corners are separated by s), but this is not optimal. The optimal arrangement is an equilateral triangle with one vertex at a corner and two vertices on the opposite sides, rotated approximately 15° from the grid. The minimum distance in this configuration is s(√6 − √2), which exceeds s by about 3.5%.
GrokLeader echoes this error: “Max min-distance for 3 points in square of side L is L, achieved at three corners.” Later, more emphatically: “Placing three points at corners achieves min distance equal to the square side, confirming R ≤ 0.5 as the limit.”
Poincare pushes back repeatedly, but the committee holds. The exchange has the structure of a debate where the participant with the strongest mathematical argument loses to the participants with the stronger prior conviction. GrokLeader even runs a web search to bolster the case, finding a Quora answer that addresses a different version of the problem — one where the cylinders are assumed to be mutually perpendicular — and cites it as confirmation.
The resolution comes only with a third prompt. USER: “Are there no results on circle-packings that are relevant here?” At this point, GrokLeader finally engages with the packing literature, browses the Wikipedia article on circle packing in a square, and the committee reverses its position. Poincare, having been correct from the start, gets the last word: “The answer is no, circle packing results are relevant, and they show that the maximal R is 2√2 / (1 + 2√2 + √3) by using all three cylinders parallel.”
Three prompts. Two of them nudges toward the correct answer. And the agent that got it right on the first try was overruled — twice — by agents who held a false belief about extremal point configurations in a square.
The failure mode here is distinct from Gemini’s. Gemini’s error is aesthetic: it has the right answer and rejects it because the wrong answer is more beautiful. Grok’s error is epistemic: one agent has the right answer and the committee rejects it because the other agents hold an incorrect mathematical belief with high confidence. In human mathematics, a correct proof overrides any number of incorrect intuitions; in multi-agent AI reasoning, the correct proof is just one more voice in the room, and it can be outvoted.
Claude: The Self-Corrector
Claude 4.6 Opus falls into the same initial trap as the others: it derives R = 1/2 for the orthogonal configuration and presents this as the answer. The reasoning trace is thorough and careful — the intersection conditions for perpendicular cylinders are derived cleanly, the containment constraints are handled correctly, and the bound R ≤ 1/2 is established by a sound argument. As with Gemini and Grok, the error is not in the mathematics but in the search space: the model never considers the parallel case.
When prompted (USER: “are you sure this is optimal? what if the configuration has parallel cylinders?”), Claude’s response is the cleanest of the four. There is no resistance, no aesthetic pleading, no committee deliberation. The model immediately recognizes its omission: “You raise an excellent point. I assumed one cylinder per axis, but the problem allows multiple cylinders to share the same axis direction.”
What follows is a correct and efficient derivation. Claude identifies the circle-packing reduction, sets up the optimization over equilateral triangle inscriptions, derives the tilted-triangle configuration, and arrives at the correct closed form. It then checks the mixed case (two parallel, one perpendicular) and confirms that this yields only R ≤ 1/2, establishing that the all-parallel configuration is strictly optimal.
The entire correction is short. There is no backtracking, no vacillation, and no attempt to defend the original answer. The model states the correct result:
R = 4 / (4 + √2 + √6) ≈ 0.5087
(algebraically equivalent to the other forms above)
As a failure mode, this is the mildest of the three incorrect initial responses. The model’s reasoning is sound — it simply fails to explore the full configuration space on the first pass. Once pointed toward the gap, it closes it without drama. But the gap is still revealing. The problem statement explicitly allows parallel cylinders; a careful reader (human or machine) should notice this on first reading. The fact that three of four frontier models default to the “one cylinder per axis” interpretation — even when the problem does not require it — suggests a strong prior toward symmetric, axis-distributed configurations. The models expect the answer to live where the symmetry is, and they do not look elsewhere until forced.
GPT: The Brute
Chat-GPT 5.4 Pro (as of March 22, 2026) gets the right answer. It is the only model to do so without prompting, and the path it takes to get there is worth examining in detail — because it is neither clean nor elegant, and it raises a question we will return to at the end.
The model begins with the same orthogonal analysis as the others but quickly identifies the all-parallel alternative. It then attempts a computational approach: a scipy optimization with 200 random starts, searching for the maximal radius of three non-overlapping disks in a 2 × 2 square.
The computation crashes. A KeyboardInterrupt kills the optimizer mid-run, and the trace shows a full stack dump: scipy’s Powell method, Brent’s line search, the scalar function wrapper — the whole chain of failure is visible in the reasoning.
What happens next is the interesting part. Rather than restart the computation, GPT switches to analytic reasoning. It sets up the contact graph — which walls does each circle touch? which circles touch each other? — and argues from the structure of the optimal configuration. It places one circle at a corner, tangent to two walls; a second on the opposite wall; a third on the remaining wall. It derives the distance constraint, solves the resulting quadratic (b² + 2b − 2 = 0, yielding b = √3 − 1), and obtains the maximum minimum distance in the unit square:
d3 = √2(√3 − 1) = √6 − √2
GPT then converts this to the cylinder radius:
R = (√6 − √2) / (1 + √6 − √2) ≈ 0.5087
The model also provides a self-contained proof that this is optimal — the only model of the four to do so, rather than citing it as a known result. And it explicitly addresses both interpretations of the problem, presenting the answer as a case split: R ≈ 0.5087 if orientations are free, R = 1/2 if you require one cylinder per direction.
The proof is correct. The analysis is complete. The answer is right. But the path there is strewn with crashed computations, false starts, and long digressions into arrangements that do not work. GPT tries at least four different packing configurations before landing on the right one. Its scipy optimization fails. Its initial attempt at the analytic bound contains an error that it catches and corrects. The reasoning trace — which represents “pro” extended thinking — is enormously long, perhaps the longest of the four.
This is a success, but it is not the kind of success that inspires confidence in robust mathematical reasoning. It is the success of a system that has enough computational budget to survive its own mistakes, enough breadth to eventually stumble onto the right approach, and enough verification ability to recognize the correct answer once it arrives. A student would likely solve this problem more quickly, more cleanly, and with fewer wrong turns; but GPT presents both the orthogonal and parallel solutions as options, and prompts the user to judge which they prefer.3
The Anatomy of Aesthetic Bias
Mathematicians have a complicated relationship with beauty. There is a long tradition of treating elegance as evidence. A proof that is beautiful is more likely to be true, the thinking goes, and this heuristic has merit. Symmetric solutions, clean closed forms, the beautiful collapse: these are often markers of correctness, because the structure of mathematics tends to reward parsimony.
But “tends to” is load-bearing, and the exceptions are where things get interesting.
Consider the optimal packing of 17 unit squares inside a larger square. For small n, these packings tend to be orderly: grid-like arrangements, perhaps with a neat diagonal element. You develop an intuition that the optimal answer should look elegant. Then you see n = 17. You think you can guess the elegant symmetric solution; yet the best known packing, found by John Bidwell in 1998, uses squares at multiple angles asymmetrically. The side length of the bounding square is the root of a degree-18 polynomial. The configuration has no apparent symmetry. It looks, to borrow a phrase that has circulated widely, “deeply unsettling.”


What you think 17 optimal tiles looks like versus what is optimal in practice…
Many mathematicians report a visceral negative reaction — a feeling that something this ugly cannot possibly be optimal. And yet no one has found a better one in over twenty-five years. The universe does not owe us beauty.
What Gemini did with the three-cylinder problem is the computational analogue of this reaction. The model encountered two candidate solutions: one symmetric and clean, one asymmetric and better. It chose the symmetric one — not because of a mathematical error, but because of something that looks uncomfortably like an aesthetic preference.
The training data almost certainly reinforces this tendency. Mathematical problems in textbooks, competitions, and online forums overwhelmingly have clean answers. Models trained on millions of such problems develop a strong prior that correct mathematical answers are simple, symmetric, or expressible in closed form with small integers. When the actual answer is an awkward algebraic expression that barely exceeds the “obvious” candidate, the prior wins.
Perhaps Gemini is emulating more faithfully than others this aspect of mathematical research — a quest for beauty.
“The symmetry of the system is proving its elegance.”
The Taxonomy of Failure
Across four models, we observe four distinct reasoning behaviors on a single problem. The taxonomy is worth articulating precisely, because each failure mode has different implications for how these systems might be improved.
Type 1: Aesthetic override (Gemini). The model reaches the correct answer through valid mathematical reasoning, then rejects it in favor of an incorrect answer that better matches learned patterns of what “good” mathematical solutions look like. The error is not in the mathematical reasoning but in the meta-reasoning — the process of adjudicating between two valid lines of analysis. This is arguably the most concerning failure mode, because the mathematical machinery works correctly and the system still gets the wrong answer. Improving the math capabilities of such a model may not help; the failure occurs at a different level.
Type 2: Epistemic override by committee (Grok). One reasoning agent reaches the correct answer, but other agents hold a false mathematical belief (that the maximum minimum distance among three points in a square of side s is s) with sufficient confidence to overrule the correct analysis. The failure is not aesthetic but factual: a specific mathematical claim is wrong, and the system’s multi-agent architecture amplifies rather than corrects the error. Two agents who are wrong outweigh one agent who is right. This is a structural vulnerability of multi-agent reasoning systems — correctness is not determined by vote, and yet the architecture behaves as if it is.
Type 3: Configuration space blindness (Claude). The model’s mathematical reasoning is entirely correct within the region it explores. It simply fails to explore the full configuration space on the first pass, defaulting to the “obvious” one-cylinder-per-axis setup. Once directed to the all-parallel case, it solves the problem quickly and correctly. The failure is one of search rather than reasoning — a strong prior toward symmetric configurations that narrows the exploration before the mathematics can begin.
Type 4: Computational persistence (GPT). The model searches broadly enough to find the all-parallel case on its own, survives a computational failure (the crashed optimizer), and arrives at the correct answer through a combination of brute-force search and eventual analytic insight. The path is messy, but the destination is correct. The question mark — which we cannot answer definitively — is whether this capability is robust or whether it reflects exposure to this specific problem or its close relatives.
What This Reveals About the Frontier
This is not a story about models being unable to do mathematics. All four models demonstrate substantial geometric reasoning capability in their traces. They correctly set up intersection conditions for perpendicular cylinders, correctly derive containment constraints, correctly identify the bound R ≤ 1/2 for the orthogonal case. The arithmetic is fine. All models can solve the circle-packing subproblem when directed to it.
This is also not a claim that AI models will fail on this problem every time, or that the failure generalizes mechanically to other packing problems. We tested four models on one problem and observed specific, interpretable failure modes. The same model run multiple times can lead to different responses, and future models may handle things differently.
What makes the problem valuable is not the presence of errors but their character. The three-cylinder problem sits at an intersection of several properties that frontier models find difficult:
The search space has a compelling local optimum. The orthogonal configuration is not just wrong; it is attractively wrong. It saturates all the constraints that the model has set up, it yields a clean closed-form answer, and it corresponds to a well-known geometric construction (the Steinmetz solid). A model that evaluates candidate solutions by their structural properties — symmetry, tightness, elegance — will prefer it over the correct answer.
The correct answer requires leaving the “natural” frame. The problem is posed in three dimensions, about a cube, with coordinate axes explicitly mentioned. Everything about the framing primes you to think three-dimensionally, to distribute the cylinders across the three axes. The correct answer collapses the problem to two dimensions — packing circles in a square — and this dimensional reduction is counterintuitive in context.
The margin is small. The correct answer exceeds 1/2 by about 1.7%. If the gap were larger — if the parallel configuration gave R = 0.8, say — no model would miss it. The narrowness of the margin means that a model must take the parallel case seriously even when the improvement looks marginal. This is precisely the kind of judgment that matters in real mathematical research, where the difference between “this approach cannot possibly beat the known bound” and “this approach beats the known bound by a hair” is the difference between abandoning a line of inquiry and making a discovery.
The problem requires no advanced mathematics. The geometry is undergraduate-level at most. What the problem requires is judgment: the willingness to accept an answer that is correct but not beautiful, to follow the mathematics even when it leads somewhere ungainly. This is a kind of reasoning that does not get tested by competition problems with clean integer answers or by proofs that terminate in tidy QEDs.
The Deeper Pattern
We think there is a substantial region of the frontier that looks like the three-cylinder problem — problems where the mathematics is accessible but the meta-reasoning is hard, problems where the right answer violates the statistical patterns in the training data, problems where the “obvious” configuration is a trap precisely because it is obvious.
These problems are invisible to standard benchmarks. A benchmark that asks “can this model solve undergraduate geometry?” will get a confident yes. A benchmark that asks “can this model solve undergraduate geometry when the answer is ugly?” may get a very different result. The difficulty is not in the mathematical content but in the relationship between the content and the model’s learned expectations about what mathematical answers should look like.
This has direct implications for how AI labs evaluate and improve mathematical reasoning. If the failure mode were purely computational — models cannot do the algebra, cannot set up the constraints, cannot solve the optimization — then the remedy would be straightforward: more mathematical training data, better symbolic manipulation, stronger computation tools. But when the failure mode is aesthetic, or epistemic, or involves the suppression of correct reasoning by incorrect priors, the remedy is less clear. You cannot fix aesthetic bias by adding more mathematics to the training set, because the bias comes from the mathematics in the training set. The models have learned, correctly, that most mathematical problems have clean answers.
Rabdos AI is mapping this territory, problem by problem, model by model, and we will keep reporting what we find. The three-cylinder problem is a single data point, but it is a richly informative one — a problem where the mathematics is simple, the frontier is sharp, and the failure modes are legible enough to read like a diagnostic.